Pure White主业写bug,副业debug2022-03-15T17:33:07.000Zhttps://www.purewhite.io/Pure WhiteHexo给大家推荐一个 B 站宝藏 up 主 —— BiBiPianohttps://www.purewhite.io/2022/03/16/bibipiano-recommend/2022-03-15T17:23:00.000Z2022-03-15T17:33:07.000Z今天想发一点和技术无关的内容,毕竟生活中也不全是工作嘛😊。
关注这个 up 主已经很久了,已经经过了很长时间的检验,在这里也推荐给大家。
这个 up 主发的所有曲子我都会第一时间听。
另外,记得一定要看简介,一定要看简介,一定要看简介!
这里我尝试使用嵌入代码给大家推荐三首曲子,不过推荐大家跳转到原页面,一边看简介一边听。
卡农(必听)
风居住的街道
可惜不是你
]]><p>今天想发一点和技术无关的内容,毕竟生活中也不全是工作嘛😊。</p>
<p>关注这个 up 主已经很久了,已经经过了很长时间的检验,在这里也推荐给大家。</p>
<p>这个 up 主发的所有曲子我都会第一时间听。</p>
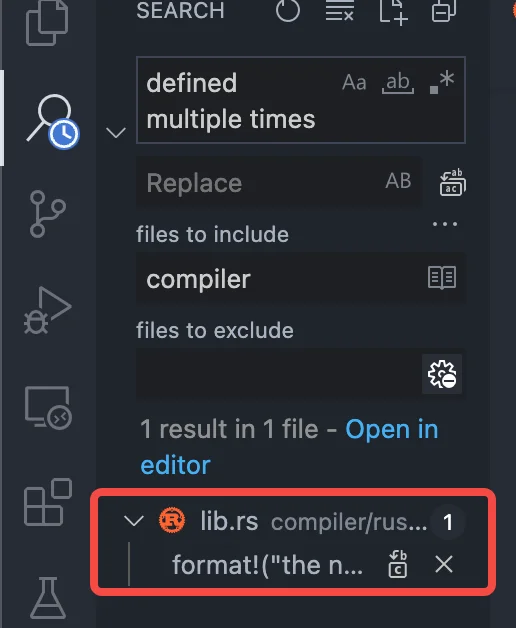
<p>另外,记得一定要看简介,一定要看简介,一定要看简介!</p>Rustc Reading Club:从一个错误出发学习 rustc_resolvehttps://www.purewhite.io/2021/11/07/rustc-resolve-reading-defined-multiple-times/2021-11-07T07:38:31.000Z2021-12-02T12:51:07.000Z最近 Rust 官方社区搞了个 Rustc Reading Club 的活动,由编译器 team 的 Leader Niko 发起,具体网址在这里:https://rust-lang.github.io/rustc-reading-club/
很可惜的是,11 月 4 日的第一期,由于太过火爆并且 Zoom 人数限制 100 人,导致主持人 Niko 自己进不来所以取消了……等待看看官方后续会怎么搞吧,还是很期待官方组织的活动的。
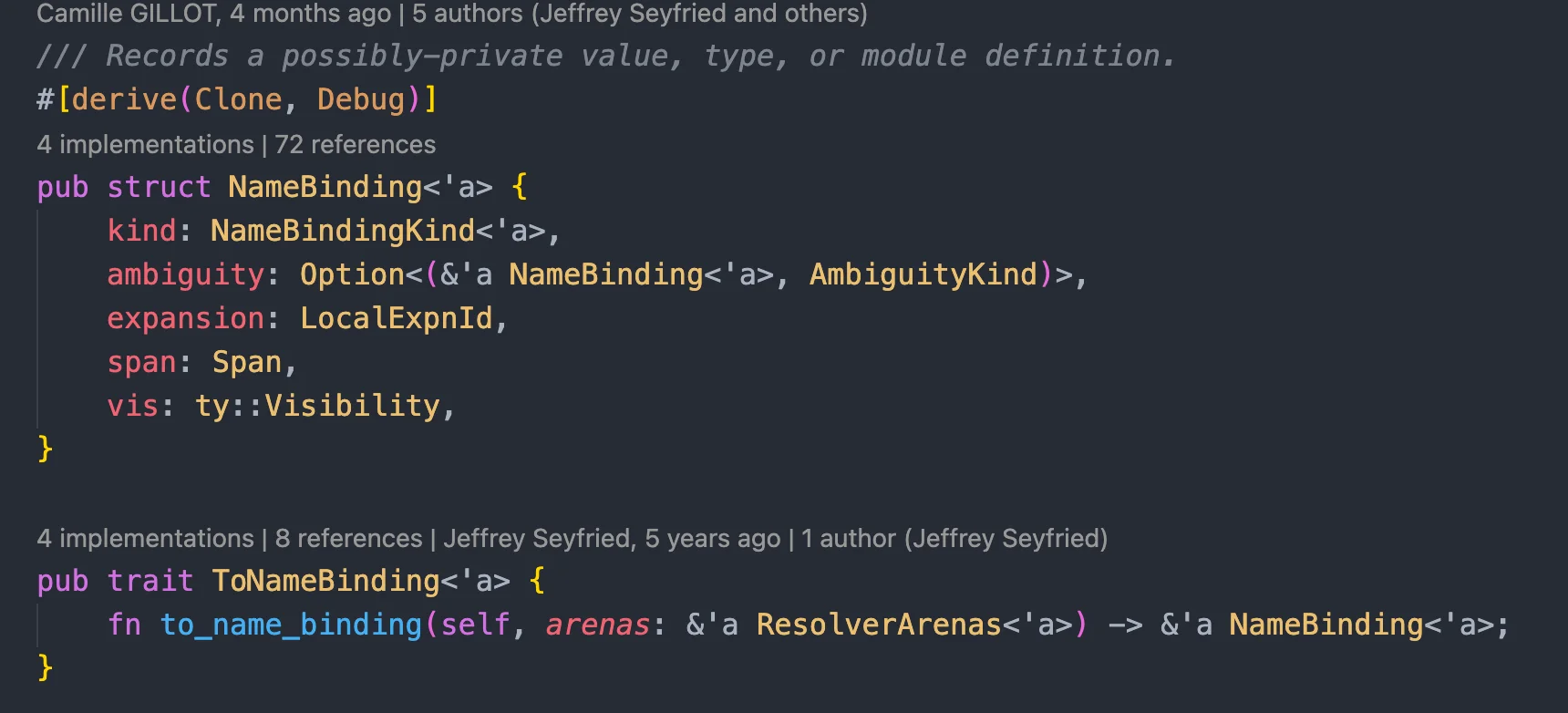
/// The resolution of a path or export. /// /// For every path or identifier in Rust, the compiler must determine /// what the path refers to. This process is called name resolution, /// and `Res` is the primary result of name resolution. /// /// For example, everything prefixed with `/* Res */` in this example has /// an associated `Res`: /// /// ``` /// fn str_to_string(s: & /* Res */ str) -> /* Res */ String { /// /* Res */ String::from(/* Res */ s) /// } /// /// /* Res */ str_to_string("hello"); /// ``` /// /// The associated `Res`s will be: /// /// - `str` will resolve to [`Res::PrimTy`]; /// - `String` will resolve to [`Res::Def`], and the `Res` will include the [`DefId`] /// for `String` as defined in the standard library; /// - `String::from` will also resolve to [`Res::Def`], with the [`DefId`] /// pointing to `String::from`; /// - `s` will resolve to [`Res::Local`]; /// - the call to `str_to_string` will resolve to [`Res::Def`], with the [`DefId`] /// pointing to the definition of `str_to_string` in the current crate. // #[derive(Clone, Copy, PartialEq, Eq, Encodable, Decodable, Hash, Debug)] #[derive(HashStable_Generic)] pubenumRes<Id = hir::HirId> { ... }
cratefncheck_reserved_macro_name(&mutself, ident: Ident, res: Res) { // Reserve some names that are not quite covered by the general check // performed on `Resolver::builtin_attrs`. if ident.name == sym::cfg || ident.name == sym::cfg_attr { letmacro_kind = self.get_macro(res).map(|ext| ext.macro_kind()); if macro_kind.is_some() && sub_namespace_match(macro_kind, Some(MacroKind::Attr)) { self.session.span_err( ident.span, &format!("name `{}` is reserved in attribute namespace", ident), ); } } }
好像也没啥特殊的,就是看看有没有用到保留关键字,先无视掉吧;
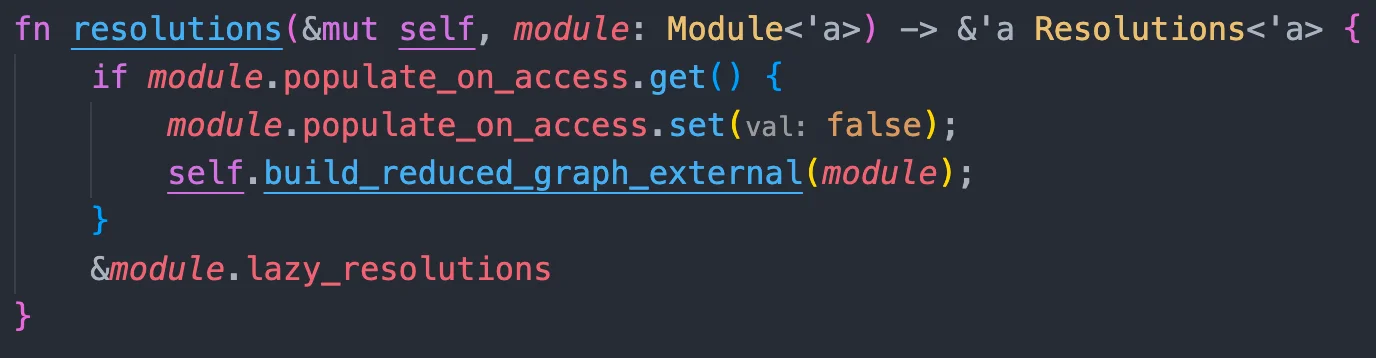
再看看第二行set_binding_parent_module:
1 2 3 4 5 6 7
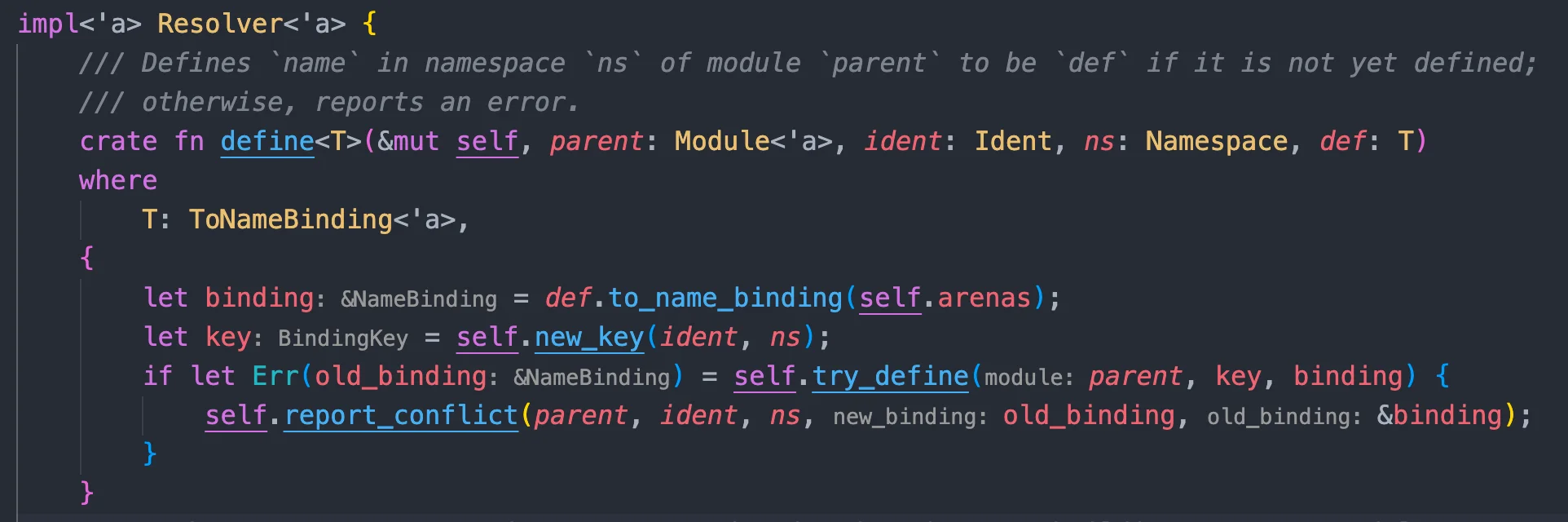
fnset_binding_parent_module(&mutself, binding: &'a NameBinding<'a>, module: Module<'a>) { ifletSome(old_module) = self.binding_parent_modules.insert(PtrKey(binding), module) { if !ptr::eq(module, old_module) { span_bug!(binding.span, "parent module is reset for binding"); } } }
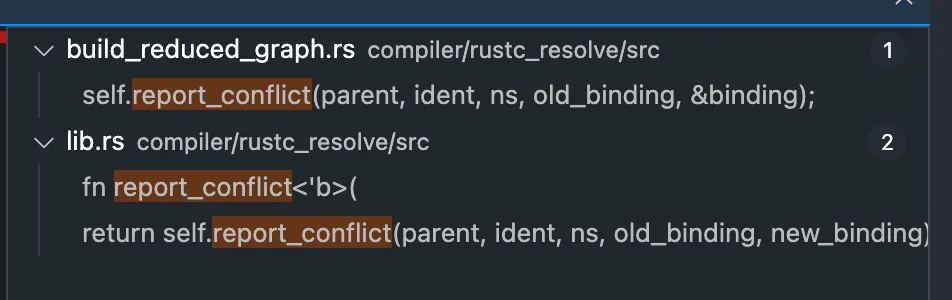
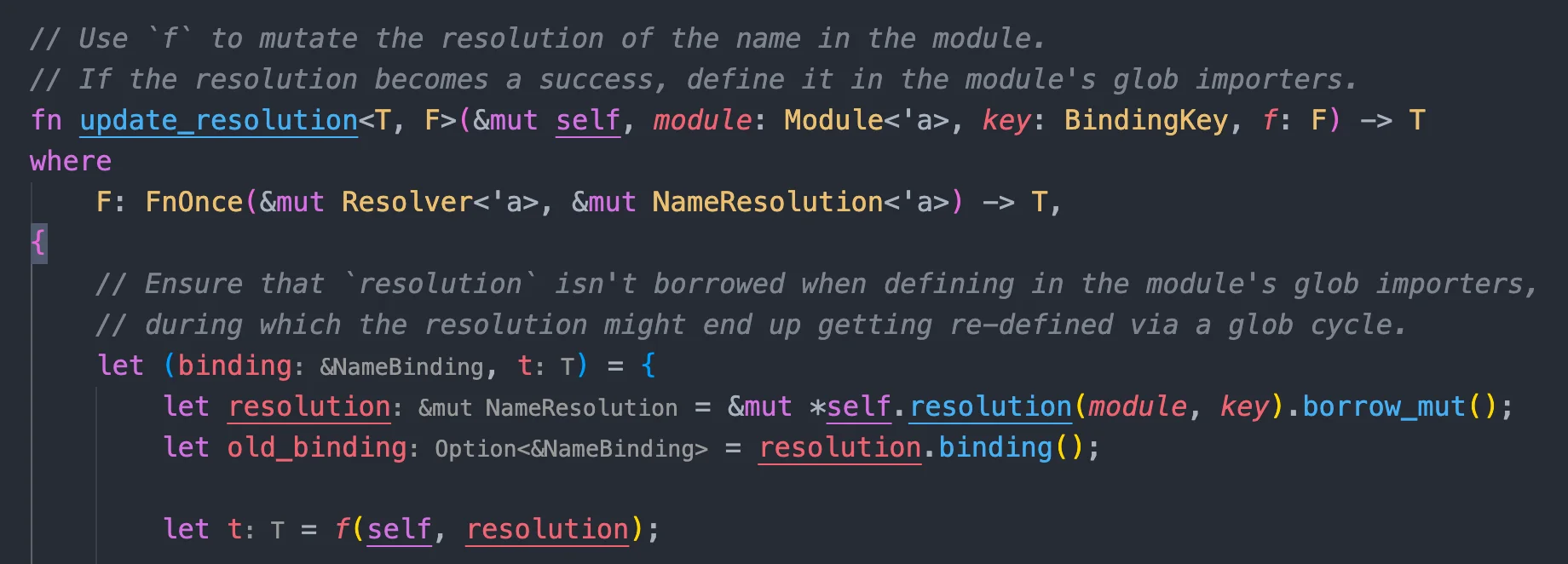
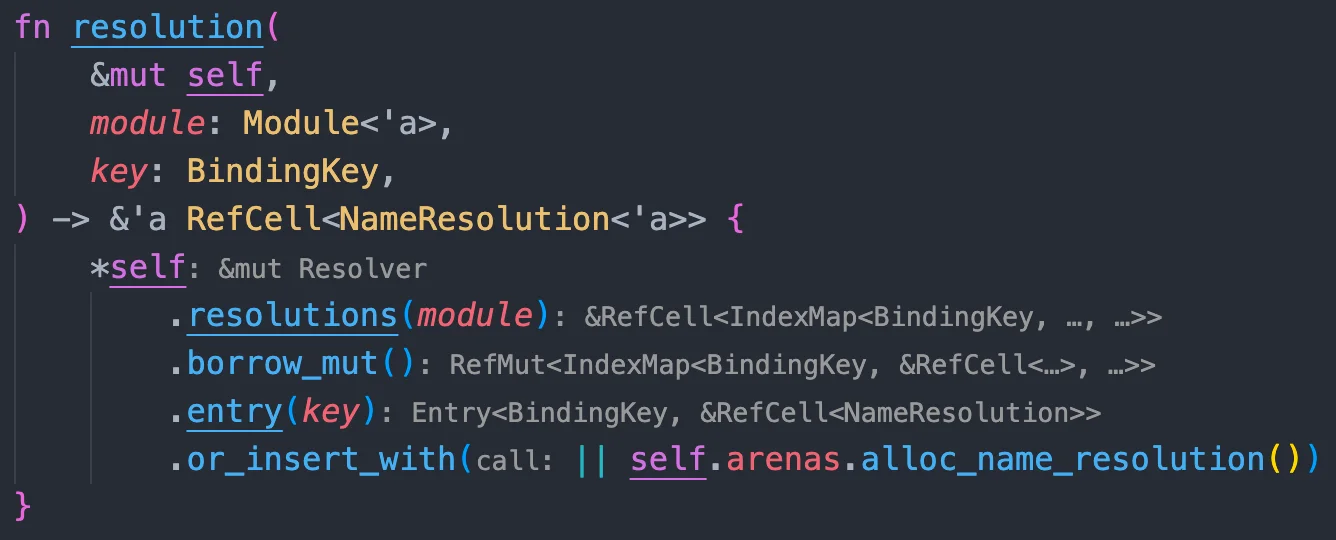
self.update_resolution(module, key, |this, resolution| { ifletSome(old_binding) = resolution.binding { if res == Res::Err { // Do not override real bindings with `Res::Err`s from error recovery. returnOk(()); } ...
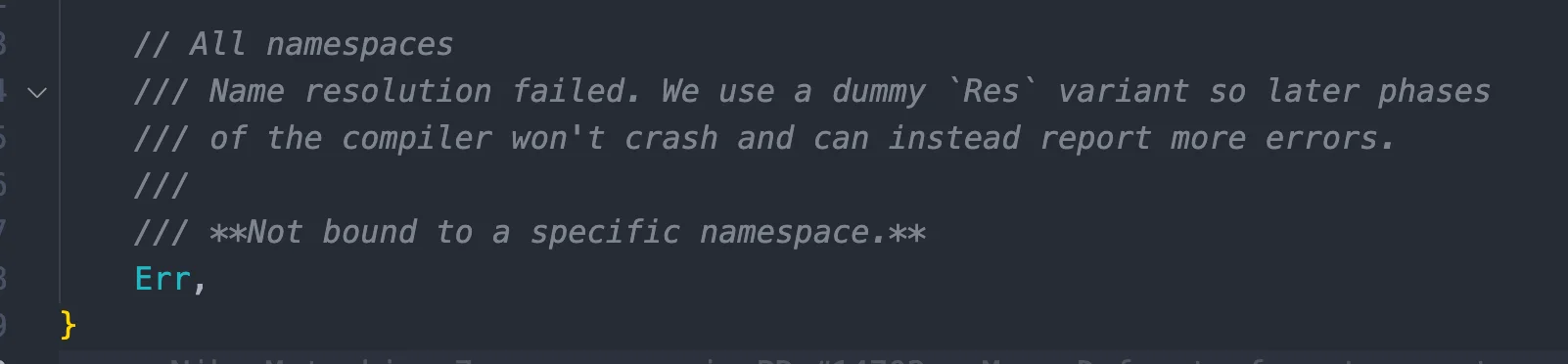
这里如果之前返回的 res 本身就是 Err 的话,就直接返回,我们看一下 Err 的注释:
嗯,这部分直接无视吧,我们接着看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
letres = binding.res(); self.update_resolution(module, key, |this, resolution| { ifletSome(old_binding) = resolution.binding { ... match (old_binding.is_glob_import(), binding.is_glob_import()) { (true, true) => { if res != old_binding.res() { resolution.binding = Some(this.ambiguity( AmbiguityKind::GlobVsGlob, old_binding, binding, )); } elseif !old_binding.vis.is_at_least(binding.vis, &*this) { // We are glob-importing the same item but with greater visibility. resolution.binding = Some(binding); } } ...
目前不能。Rust 的宏是“卫生宏”,它有意避免捕捉或创建可能与其他标识符发生意外碰撞的标识符。它们的功能与通常与 C 预处理器相关的宏的风格明显不同。宏调用只能出现在被明确支持的地方:项目、方法声明、语句、表达式和模式。这里,“方法声明”指的是可以放置方法的空白处。它们不能被用来完成部分方法声明。按照同样的逻辑,它们也不能用来完成一个部分变量声明。
这确实应该在内存使用方面与 C 语言大致相同,但代价是更多的程序员复杂性,以及缺乏通常由 Rust 提供的静态保证(在这里通过使用unsafe来避免)。
为什么 Rust 不像 C 那样有一个稳定的 ABI,为什么我必须用 extern 来注解东西?
对 ABI 的承诺是一个重大的决定,会限制未来潜在的有利的语言变化。鉴于 Rust 在 2015 年 5 月才达到 1.0,现在做出像稳定 ABI 这样大的承诺还为时过早。但这并不意味着未来不会发生。(尽管 C++ 已经成功地运行了很多年而没有指定一个稳定的 ABI)。
extern关键字允许 Rust 使用特定的 ABI,例如定义明确的 C ABI,以便与其他语言互操作。
Rust 代码可以调用 C 代码吗?
可以。从 Rust 中调用 C 代码的设计与从 C++ 中调用 C 代码一样高效。
C 代码可以调用 Rust 代码吗?
是的,Rust 代码必须通过“extern”声明公开,这使得它与 C-ABI 兼容。这样的函数可以作为一个函数指针传递给 C 代码,或者,如果赋予#[no_mangle]属性以禁用符号纠缠,可以直接从 C 代码中调用。
我已经写了完美的 C++ 代码。Rust 能给我什么?
现代 C++ 包含了许多使编写安全和正确的代码不容易出错的特性,但它并不完美,而且仍然很容易引入不安全因素。这是 C++ 的核心开发人员正在努力克服的问题,但是 C++ 受限于悠久的历史,它比他们现在试图实现的很多想法都要早。
Rust 从第一天起就被设计成一种安全的系统编程语言,这意味着它不会受到历史上的设计决定的限制,而这些决定使 C++ 的安全问题变得如此复杂。在 C++ 中,安全是通过谨慎的个人纪律实现的,而且很容易出错。在 Rust 中,安全是默认的。它让你有能力在一个包括不如你完美的人在内的团队中工作,而不必花时间反复检查他们的代码是否存在安全漏洞。
C++ 采取了一种不同的方法。在 C++ 中,默认的做法是复制一个值(更确切地说,是调用复制构造函数)。然而,被调用者可以使用一个“rvalue reference”来声明他们的参数,例如string&&,以表明他们将获得该参数所拥有的一些资源的所有权(在这个例子中,字符串的内部缓冲区)。然后调用者必须传递一个临时表达式或使用std::move进行明确的移动。大致相当于上面的函数process的粗略等价物是:
C++ 编译器没有义务去跟踪移动。例如,上面的代码在编译时没有任何警告或错误,至少在使用默认的设置的情况下,上述代码在编译时没有任何警告或错误。此外,在C++中,字符串s本身的所有权(如果不是它的内部缓冲区的话)仍然属于caller,所以s的析构函数会在caller返回时运行,即使它已经被移动了(相反,在 Rust 中,被移动的值只被其新主人丢弃)。
我怎样才能从 Rust 与 C++ 互操作,或者从 C++ 与 Rust 互操作?
Rust 和 C++ 可以通过 C 语言进行互操作。Rust 和 C++ 都为 C 语言提供了一个外来函数接口,并可以用它来进行相互之间的通信。如果编写 C 语言绑定太过繁琐,你可以使用rust-bindgen来帮助自动生成可行的 C 语言绑定。
不完全是。实现了Copy的类型会做一个标准的类似于 C 语言的“浅拷贝”,不需要额外的工作(类似于 C++ 中的 trivially copyable 类型)。不可能实现需要自定义复制行为的Copy类型。相反,在 Rust 中,“复制构造器”是通过实现Clone特性,并明确调用clone方法来创建的。将用户定义的复制操作符显性化,使开发者更容易识别潜在的昂贵操作。
]]><p>大家应该都听说过 Rust 语言是以安全(Safe)作为特性之一的,但是由于一个悲哀的事实——硬件是不安全(Unsafe)的,所以其实所有的“安全”一定是在“不安全”之上的封装,这也导致了完全意义上的“Safe”是很难做到且功能极其受限的。</p>
<p>那让我们来看看,Rust 的 Safe 边界在哪里。</p>【译】Inventing the Service traithttps://www.purewhite.io/2021/05/24/inventing-the-service-trait/2021-05-24T08:21:59.000Z2021-12-02T12:51:07.000Z
error[E0759]: `self` has an anonymous lifetime `'_` but it needs to satisfy a `'static` lifetime requirement --> src/lib.rs:145:29 | 144 | fncall(&mutself, request: HttpRequest) ->Self::Future { | --------- this data with an anonymous lifetime `'_`... 145 | Box::pin(asyncmove { | _____________________________^ 146 | | letresult = tokio::time::timeout( 147 | | self.duration, 148 | | self.inner_handler.call(request), ... | 155 | | } 156 | | }) | |_________^ ...is captured here, requiring it to live as long as `'static`
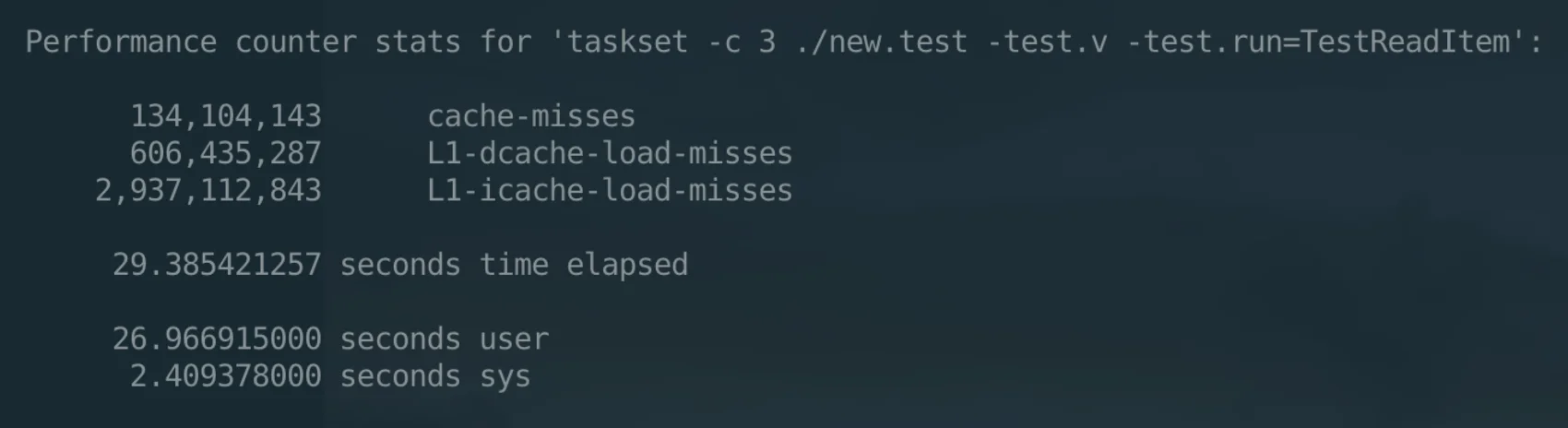
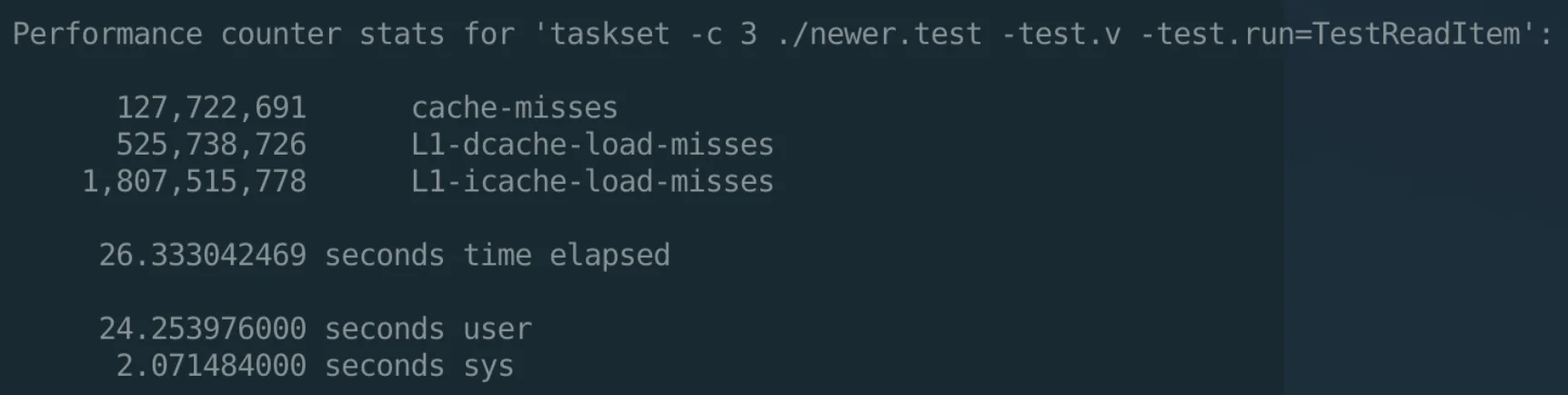
// func walltime1() (sec int64, nsec int32) // non-zero frame-size means bp is saved and restored TEXT runtime·walltime1(SB),NOSPLIT,$16-12 // We don't know how much stack space the VDSO code will need, // so switch to g0. // In particular, a kernel configured with CONFIG_OPTIMIZE_INLINING=n // and hardening can use a full page of stack space in gettime_sym // due to stack probes inserted to avoid stack/heap collisions. // See issue #20427.
MOVQSP, R12// Save old SP; R12 unchanged by C code.
get_tls(CX) MOVQg(CX), AX MOVQg_m(AX), BX // BX unchanged by C code.
// Set vdsoPC and vdsoSP for SIGPROF traceback. // Save the old values on stack and restore them on exit, // so this function is reentrant. MOVQm_vdsoPC(BX), CX MOVQm_vdsoSP(BX), DX MOVQCX, 0(SP) MOVQDX, 8(SP)
CMPQAX, m_curg(BX)// Only switch if on curg. JNEnoswitch
MOVQm_g0(BX), DX MOVQ(g_sched+gobuf_sp)(DX), SP// Set SP to g0 stack
noswitch: SUBQ$16, SP// Space for results ANDQ$~15, SP// Align for C code
MOVL$0, DI // CLOCK_REALTIME LEAQ0(SP), SI MOVQruntime·vdsoClockgettimeSym(SB), AX CMPQAX, $0 JEQfallback CALLAX ret: MOVQ0(SP), AX// sec MOVQ8(SP), DX// nsec MOVQR12, SP// Restore real SP // Restore vdsoPC, vdsoSP // We don't worry about being signaled between the two stores. // If we are not in a signal handler, we'll restore vdsoSP to 0, // and no one will care about vdsoPC. If we are in a signal handler, // we cannot receive another signal. MOVQ8(SP), CX MOVQCX, m_vdsoSP(BX) MOVQ0(SP), CX MOVQCX, m_vdsoPC(BX) MOVQAX, sec+0(FP) MOVLDX, nsec+8(FP) RET fallback: MOVQ$SYS_clock_gettime, AX SYSCALL JMP ret
这段代码的注释非常的清晰,根据这段代码,可以看到,实际上是使用的vdso call来获取到当前的时间信息。只不过,由于 Go 是自己维护的协程的栈,而这个栈在某些内核上调用vdso会出问题,所以需要先切换到g0(也就是系统线程的栈)上才行。所以这里在开头和结尾有很多额外的操作,需要制造和清理作案现场。
noswitch: SUBQ$16, SP// Space for results ANDQ$~15, SP// Align for C code
MOVL$1, DI // CLOCK_MONOTONIC LEAQ0(SP), SI MOVQruntime·vdsoClockgettimeSym(SB), AX CMPQAX, $0 JEQfallback CALLAX ret: MOVQ0(SP), AX// sec MOVQ8(SP), DX// nsec MOVQR12, SP// Restore real SP // Restore vdsoPC, vdsoSP // We don't worry about being signaled between the two stores. // If we are not in a signal handler, we'll restore vdsoSP to 0, // and no one will care about vdsoPC. If we are in a signal handler, // we cannot receive another signal. MOVQ8(SP), CX MOVQCX, m_vdsoSP(BX) MOVQ0(SP), CX MOVQCX, m_vdsoPC(BX) // sec is in AX, nsec in DX // return nsec in AX IMULQ$1000000000, AX ADDQDX, AX MOVQAX, ret+0(FP) RET
回到开头,我是想自己实现clock_gettime的CLOCK_REALTIME_COARSE和CLOCK_MONOTONIC_COARSE,这就需要我在runtime包外部实现以上的一系列操作。但是如果要这么干,就需要把所有runtime包里面的结构体定义全部复制一份(这样在汇编代码里面 include 的 go_asm.h才有对应的偏移量),这样可维护性太差了,而且如果某个版本调整了结构体的顺序,行为就不可定义,太危险了,要不就得每个版本单独复制一份出来。
针对这个问题,也和 Go 官方进行了讨论,最终确实没有什么太好的思路,Go 目前不支持在runtime外部安全地调用vdso。
funcinsertKeys() { keys := make([]interface{}, 0, 10) // Store some keys for i := 0; i < 10; i++ { v := make([]int, 1000) keys = append(keys, &v) sm.Store(keys[i], struct{}{}) } // delete some keys, but not all keys for i, k := range keys { if i%2 == 0 { continue } sm.Delete(k) } }
funcshutdown() { sm.Range(func(key, value interface{})bool { // do something to key returntrue }) }
funcmain() { insertKeys() // do something ... shutdown() }
// LoadAndDelete deletes the value for a key, returning the previous value if any. // The loaded result reports whether the key was present. func(m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) { read, _ := m.read.Load().(readOnly) e, ok := read.m[key] if !ok && read.amended { m.mu.Lock() read, _ = m.read.Load().(readOnly) e, ok = read.m[key] if !ok && read.amended { e, ok = m.dirty[key] // Regardless of whether the entry was present, record a miss: this key // will take the slow path until the dirty map is promoted to the read // map. m.missLocked() } m.mu.Unlock() } if ok { return e.delete() } returnnil, false }
// Delete deletes the value for a key. func(m *Map) Delete(key interface{}) { m.LoadAndDelete(key) }
func(e *entry)delete() (value interface{}, ok bool) { for { p := atomic.LoadPointer(&e.p) if p == nil || p == expunged { returnnil, false } if atomic.CompareAndSwapPointer(&e.p, p, nil) { return *(*interface{})(p), true } } }
// Delete deletes the value for a key. func(m *Map) Delete(key interface{}) { read, _ := m.read.Load().(readOnly) e, ok := read.m[key] if !ok && read.amended { m.mu.Lock() read, _ = m.read.Load().(readOnly) e, ok = read.m[key] if !ok && read.amended { delete(m.dirty, key) } m.mu.Unlock() } if ok { e.delete() } }
这段代码中,初看起来貌似在 main 函数中(不考虑 newFuncContainer 函数中导致的内存分配)没有运行时内存分配(m 会被优化成全局区,所以不会真的导致运行时内存分配),但是实际上在 main 中是有两次运行时内存分配的,这是怎么回事呢?
函数还能逃逸到堆上?
我们用-gcflags="-m"来打印一下编译器的优化信息,可以看到:
1 2 3 4 5 6 7
./main.go:13:7: m does not escape ./main.go:32:23: leaking param: f ./main.go:33:7: &myFuncContainer literal escapes to heap ./main.go:39:7: &myFuncImplStruct literal escapes to heap ./main.go:42:26: m.myFunc escapes to heap ./main.go:43:27: m2.myFunc2 escapes to heap <autogenerated>:1: .this does not escape
funcmain() { // direct call of top-level func TopLevel(1)
// direct call of method with value receiver (two spellings, but same) var v Value v.M(1) Value.M(v, 1)
// direct call of method with pointer receiver (two spellings, but same) var p Pointer (&p).M(1) (*Pointer).M(&p, 1)
// indirect call of func value (×4) f1 := TopLevel f1(1) f2 := Value.M f2(v, 1) f3 := (*Pointer).M f3(&p, 1) f4 := literal f4(1)
// indirect call of method on interface (×3) var i Interface i = v i.M(1) i = &v i.M(1) i = &p i.M(1) Interface.M(i, 1) Interface.M(v, 1) Interface.M(&p, 1) }
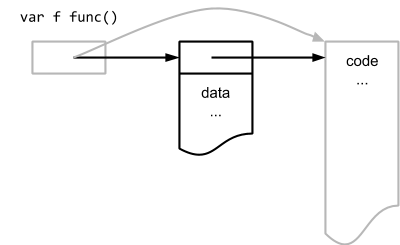
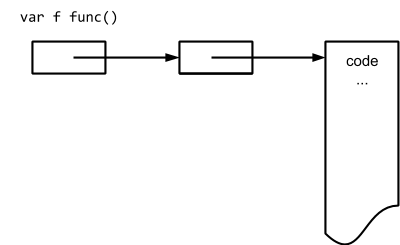
注意上述 LEAQtype.noalg.struct { F uintptr; R *"".myFuncImplStruct }(SB), AX这段代码,咱也别管啥意思,反正看到了一个和之前说的适配器很像的一个 struct,这个 struct 有两个字段,第一个是F uintptr,第二个是R *myFuncImplStruct;下面还有一个LEAQtype.noalg.struct { F uintptr; R "".myFuncImplStruct }(SB), AX,只不过这里的 R 是myFuncImplStruct的值而不是指针,这正好和我们代码吻合。
一个M就是一个系统的线程,系统线程可以执行用户的 go 代码、runtime 代码、系统调用或者空闲等待。在 runtime 中通过类型m来表示。在同一时间,可能有任意数量的M,因为任意数量的M可能会阻塞在系统调用中。(译者注:当一个M执行阻塞的系统调用时,会将M和P解绑,并创建出一个新的M来执行P上的其它G。)
最后,一个P代表了执行用户 go 代码所需要的资源,比如调度器状态、内存分配器状态等。在 runtime 中通过类型p来表示。P的数量精确地(exactly)等于GOMAXPROCS。一个P可以被理解为是操作系统调度器中的 CPU,p类型可以被理解为是每个 CPU 的状态。在这里可以放一些需要高效共享但并不是针对每个P(Per P)或者每个M(Per M)的状态(译者注:意思是,可以放一些以P级别共享的数据)。
调度器的工作是将一个G(需要执行的代码)、一个M(代码执行的地方)和一个P(代码执行所需要的权限和资源)结合起来。当一个M停止执行用户代码的时候(比如进入阻塞的系统调用的时候),就需要把它的P归还到空闲的P池中;为了继续执行用户的 go 代码(比如从阻塞的系统调用退出的时候),就需要从空闲的P池中获取一个P。
如果内存不在一个类型安全的状态,意思是可能由于刚被分配,并且第一次初始化使用,会含有一些垃圾值(译者注:这个概念在日常的 Go 代码中是遇不到的,如果学过 C 语言的同学应该能理解什么意思),那么这片内存必须使用memclrNoHeapPointers进行zero-initialized或者无指针的写。这不会触发写屏障(译者注:写屏障是 GC 中的一个概念)。
echo "branch name is: $1" if [[ ! $1 =~ ^(((feature|bugfix|test|hotfix)/.+)|(master|develop)|(release-v[0-9]+\.[0-9]+)|(release/v[0-9]+\.[0-9]+\.[0-9]+(-[a-z0-9.]+(\+[a-z0-9.]+)?)?))$ ]]; then echo "branch name invalid!" >&2 exit 1 fi
$ go build -gcflags '-m -m' unsafe.go # command-line-arguments ./unsafe.go:16:6: cannot inline f: marked go:noinline ./unsafe.go:23:6: cannot inline f2: marked go:noinline ./unsafe.go:8:6: cannot inline main: function too complex: cost 260 exceeds budget 80 ./unsafe.go:11:13: inlining call to fmt.Println func(...interface {}) (int, error) { return fmt.Fprintln(io.Writer(os.Stdout), fmt.a...) } ./unsafe.go:12:13: inlining call to fmt.Println func(...interface {}) (int, error) { return fmt.Fprintln(io.Writer(os.Stdout), fmt.a...) } ./unsafe.go:18:22: &d escapes to heap ./unsafe.go:18:22: from p (assigned) at ./unsafe.go:18:4 ./unsafe.go:18:22: from ~r0 (return) at ./unsafe.go:19:2 ./unsafe.go:17:2: moved to heap: d ./unsafe.go:25:30: f2 &d does not escape ./unsafe.go:11:13: a escapes to heap ./unsafe.go:11:13: from ~arg0 (assign-pair) at ./unsafe.go:11:13 ./unsafe.go:11:13: io.Writer(os.Stdout) escapes to heap ./unsafe.go:11:13: from io.Writer(os.Stdout) (passed to call[argument escapes]) at ./unsafe.go:11:13 ./unsafe.go:12:13: io.Writer(os.Stdout) escapes to heap ./unsafe.go:12:13: from io.Writer(os.Stdout) (passed to call[argument escapes]) at ./unsafe.go:12:13 ./unsafe.go:12:13: b escapes to heap ./unsafe.go:12:13: from ~arg0 (assign-pair) at ./unsafe.go:12:13 ./unsafe.go:12:13: from []interface {} literal (slice-literal-element) at ./unsafe.go:12:13 ./unsafe.go:12:13: from fmt.a (assigned) at ./unsafe.go:12:13 ./unsafe.go:12:13: from *fmt.a (indirection) at ./unsafe.go:12:13 ./unsafe.go:12:13: from fmt.a (passed to call[argument content escapes]) at ./unsafe.go:12:13 ./unsafe.go:11:13: main []interface {} literal does not escape ./unsafe.go:12:13: main []interface {} literal does not escape <autogenerated>:1: os.(*File).close .this does not escape
// Mutex fairness. // // Mutex can be in 2 modes of operations: normal and starvation. // In normal mode waiters are queued in FIFO order, but a woken up waiter // does not own the mutex and competes with new arriving goroutines over // the ownership. New arriving goroutines have an advantage -- they are // already running on CPU and there can be lots of them, so a woken up // waiter has good chances of losing. In such case it is queued at front // of the wait queue. If a waiter fails to acquire the mutex for more than 1ms, // it switches mutex to the starvation mode. // // In starvation mode ownership of the mutex is directly handed off from // the unlocking goroutine to the waiter at the front of the queue. // New arriving goroutines don't try to acquire the mutex even if it appears // to be unlocked, and don't try to spin. Instead they queue themselves at // the tail of the wait queue. // // If a waiter receives ownership of the mutex and sees that either // (1) it is the last waiter in the queue, or (2) it waited for less than 1 ms, // it switches mutex back to normal operation mode. // // Normal mode has considerably better performance as a goroutine can acquire // a mutex several times in a row even if there are blocked waiters. // Starvation mode is important to prevent pathological cases of tail latency.
// A Mutex is a mutual exclusion lock. // The zero value for a Mutex is an unlocked mutex. // // A Mutex must not be copied after first use. type Mutex struct { state int32 semauint32 }
// Lock locks m. // If the lock is already in use, the calling goroutine // blocks until the mutex is available. func(m *Mutex) Lock() { // Fast path: grab unlocked mutex. if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) { if race.Enabled { race.Acquire(unsafe.Pointer(m)) } return } ... }
// Lock locks m. // If the lock is already in use, the calling goroutine // blocks until the mutex is available. func(m *Mutex) Lock() { // Fast path: grab unlocked mutex. if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) { if race.Enabled { race.Acquire(unsafe.Pointer(m)) } return }
// 用来存当前goroutine等待的时间 var waitStartTime int64 // 用来存当前goroutine是否饥饿 starving := false // 用来存当前goroutine是否已唤醒 awoke := false // 用来存当前goroutine的循环次数(想一想一个goroutine如果循环了2147483648次咋办……) iter := 0 // 复制一下当前锁的状态 old := m.state // 自旋 for { // 如果是饥饿情况之下,就不要自旋了,因为锁会直接交给队列头部的goroutine // 如果锁是被获取状态,并且满足自旋条件(canSpin见后文分析),那么就自旋等锁 // 伪代码:if isLocked() and isNotStarving() and canSpin() if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) { // 将自己的状态以及锁的状态设置为唤醒,这样当Unlock的时候就不会去唤醒其它被阻塞的goroutine了 if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 && atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) { awoke = true } // 进行自旋(分析见后文) runtime_doSpin() iter++ // 更新锁的状态(有可能在自旋的这段时间之内锁的状态已经被其它goroutine改变) old = m.state continue }
$ go build -gcflags '-m' escape.go # command-line-arguments ./escape.go:3:6: can inline main ./escape.go:11:9: &i escapes to heap ./escape.go:10:2: moved to heap: i
classSolution: """ @param: x: the base number @param: n: the power number @return: the result """ defmyPow(self, x, n): if n == 0: return1 if x == 0: return0 t = x if n < 0: t = 1 / t n = -n ans = 1 while n != 0: if n % 2 != 0: ans *= t t *= t n = int(n / 2) return ans
classSolution: """ @param A: an integer array @param target: An integer @param k: An integer @return: an integer array """ defkClosestNumbers(self, A, target, k): if k == 0: return [] ifnot A: return [] lp = None rp = None start = 0 end = len(A) - 1 while start + 1 < end: mid = int(start + (end - start) / 2) if A[mid] == target: start = mid end = mid + 1 break elif A[mid] < target: start = mid else: end = mid ifabs(A[start] - target) <= abs(A[start] - target): lp = start rp = end else: lp = end rp = end + 1 cnt = 0 ans = list() while cnt < k: cnt += 1 if lp < 0and rp >= len(A): return [] elif lp < 0: ans.append(A[rp]) rp += 1 elif rp >= len(A): ans.append(A[lp]) lp -= 1 elifabs(A[lp] - target) <= abs(A[rp] - target): ans.append(A[lp]) lp -= 1 else: ans.append(A[rp]) rp += 1 return ans
]]><h1 id="题意"><a href="#题意" class="headerlink" title="题意"></a>题意</h1><p>给一个目标数 target, 一个非负整数 <code>k</code>, 一个按照升序排列的数组 A。在A中找与target最接近的k个整数。返回这k个数并按照与target的接近程度从小到大排序,如果接近程度相当,那么小的数排在前面。</p>
<h5 id="注意事项"><a href="#注意事项" class="headerlink" title="注意事项"></a>注意事项</h5><p>The value k is a non-negative integer and will always be smaller than the length of the sorted array.</p>
<p>Length of the given array is positive and will not exceed 10^4</p>
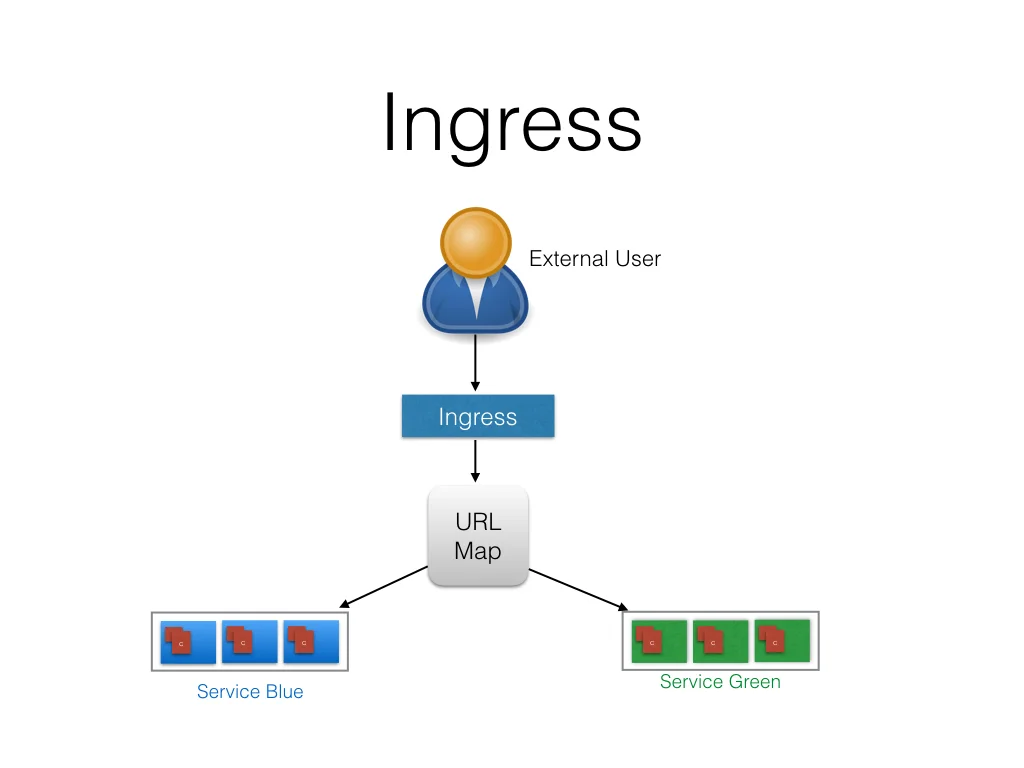
<p>Absolute value of elements in the array and x will not exceed 10^4</p>Service Mesh Istio 初探https://www.purewhite.io/2018/06/27/service-mesh-0/2018-06-27T03:41:13.000Z2021-12-02T12:51:07.000Z早在去年,Service Mesh这个概念就开始火起来了,今年的时候Service Mesh更是爆发式地发展,Service Mesh中的明星项目Istio更是只用了几个月的时间就已经从0.1到了0.8 LTS了。由于工作和毕业的压力,之前一直没有时间深入研究Service Mesh。现在稍微有些时间了,所以打算写点什么关于Service Mesh的。
# Copyright 2017 Istio Authors # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License.
classSolution: """ @param s: A string @return: Whether the string is a valid palindrome """ defisPalindrome(self, s): # edge condition if s == "": returnTrue # pre-process real = [ch.lower() for ch in s if ch.isalnum()] # solve i = 0 j = len(real) - 1 while i <= j: if real[i] != real[j]: returnFalse i += 1 j -= 1 returnTrue
classSolution: """ @param s: a string which consists of lowercase or uppercase letters @return: the length of the longest palindromes that can be built """ deflongestPalindrome(self, s): odd = list() for ch in s: if ch notin odd: odd.append(ch) else: odd.remove(ch)
num = len(odd) if num > 0: num -= 1 returnlen(s) - num
]]><h1 id="题意"><a href="#题意" class="headerlink" title="题意"></a>题意</h1><p>给出一个包含大小写字母的字符串。求出由这些字母构成的最长的回文串的长度是多少。</p>
<p>数据是大小写敏感的,也就是说,<code>"Aa"</code> 并不会被认为是一个回文串。</p>
<h5 id="注意事项"><a href="#注意事项" class="headerlink" title="注意事项"></a>注意事项</h5><p>假设字符串的长度不会超过 <code>1010</code>。</p>如何使用Helm进行本地开发https://www.purewhite.io/2018/01/17/helm-local-dev/2018-01-17T04:49:30.000Z2021-12-02T12:51:07.000ZHelm是kubernetes的官方包管理工具。根据官网上的描述Helm is the best way to find, share, and use software built for Kubernetes.可以看出helm在kubernetes社区中的定位。
wordpress/ Chart.yaml # A YAML file containing information about the chart LICENSE# OPTIONAL: A plain text file containing the license for the chart README.md # OPTIONAL: A human-readable README file requirements.yaml # OPTIONAL: A YAML file listing dependencies for the chart values.yaml # The default configuration values for this chart charts/ # OPTIONAL: A directory containing any charts upon which this chart depends. templates/ # OPTIONAL: A directory of templates that, when combined with values, # will generate valid Kubernetes manifest files. templates/NOTES.txt # OPTIONAL: A plain text file containing short usage notes
name:Thenameofthechart(required) version:ASemVer2version(required) description:Asingle-sentencedescriptionofthisproject(optional) keywords: -Alistofkeywordsaboutthisproject(optional) home:TheURLofthisproject'shomepage(optional) sources: -AlistofURLstosourcecodeforthisproject(optional) maintainers:# (optional) -name:Themaintainer'sname(requiredforeachmaintainer) email:Themaintainer'semail(optionalforeachmaintainer) url:AURLforthemaintainer(optionalforeachmaintainer) engine:gotpl# The name of the template engine (optional, defaults to gotpl) icon:AURLtoanSVGorPNGimagetobeusedasanicon(optional). appVersion:Theversionoftheappthatthiscontains(optional).Thisneedn'tbeSemVer. deprecated:Whetherornotthischartisdeprecated(optional,boolean) tillerVersion: The version of Tiller that this chart requires. This should be expressed as a SemVer range:">2.0.0"(optional)
MySQL can be accessed via port 3306 on the following DNS name from within your cluster: {{ template "mysql.fullname" . }}.{{ .Release.Namespace }}.svc.cluster.local
3. Connect using the mysql cli, then provide your password: $ mysql -h {{ template "mysql.fullname" . }} -p
To connect to your database directly from outside the K8s cluster: {{- if contains "NodePort" .Values.service.type }} MYSQL_HOST=$(kubectl get nodes --namespace {{ .Release.Namespace }} -o jsonpath='{.items[0].status.addresses[0].address}') MYSQL_PORT=$(kubectl get svc --namespace {{ .Release.Namespace }} {{ template "mysql.fullname" . }} -o jsonpath='{.spec.ports[0].nodePort}')
Helm charts store their dependencies in 'charts/'. For chart developers, it is often easier to manage a single dependency file ('requirements.yaml') which declares all dependencies.
The dependency commands operate on that file, making it easy to synchronize between the desired dependencies and the actual dependencies stored in the 'charts/' directory.
A 'requirements.yaml' file is a YAML file in which developers can declare chart dependencies, along with the location of the chart and the desired version. For example, this requirements file declares two dependencies:
The 'name' should be the name of a chart, where that name must match the name in that chart's 'Chart.yaml' file.
The 'version' field should contain a semantic version or version range.
The 'repository' URL should point to a Chart Repository. Helm expects that by appending '/index.yaml' to the URL, it should be able to retrieve the chart repository's index. Note: 'repository' can be an alias. The alias must start with 'alias:' or '@'.
Starting from 2.2.0, repository can be defined as the path to the directory of the dependency charts stored locally. The path should start with a prefix of "file://". For example,
If the dependency chart is retrieved locally, it is not required to have the repository added to helm by "helm add repo". Version matching is also supported for this case.
Usage: helm dependency [command]
Aliases: dependency, dep, dependencies
Available Commands: build rebuild the charts/ directory based on the requirements.lock file list list the dependencies for the given chart update update charts/ based on the contents of requirements.yaml
Flags: -h, --help help for dependency
Use "helm dependency [command] --help" for more information about a command.
$ helm package --help This command packages a chart into a versioned chart archive file. If a path is given, this will look at that path for a chart (which must contain a Chart.yaml file) and then package that directory.
If no path is given, this will look in the present working directory for a Chart.yaml file, and (if found) build the current directory into a chart.
Versioned chart archives are used by Helm package repositories.
Usage: helm package [flags] [CHART_PATH] [...]
Flags: -u, --dependency-update update dependencies from "requirements.yaml" to dir "charts/" before packaging -d, --destination string location to write the chart. (default ".") --key string name of the key to use when signing. Used if --sign is true --keyring string location of a public keyring (default "/Users/daniel/.gnupg/pubring.gpg") --save save packaged chart to local chart repository (default true) --sign use a PGP private key to sign this package --version string set the version on the chart to this semver version
我们还是用刚才的myweb作为例子:
1 2
$ helm package myweb Successfully packaged chart and saved it to: /Users/daniel/Works/k8s/helm/myweb-0.1.0.tgz
$ helm template --help Render chart templates locally and display the output.
This does not require Tiller. However, any values that would normally be looked up or retrieved in-cluster will be faked locally. Additionally, none of the server-side testing of chart validity (e.g. whether an API is supported) is done.
To render just one template in a chart, use '-x': $ helm template mychart -x templates/deployment.yaml
Usage: helm template [flags] CHART
Flags: -x, --execute stringArray only execute the given templates --kube-version string override the Kubernetes version used as Capabilities.KubeVersion.Major/Minor (e.g. 1.7) -n, --name string release name (default "RELEASE-NAME") --name-template string specify template used to name the release --namespace string namespace to install the release into --notes show the computed NOTES.txt file as well --set stringArray set values on the command line (can specify multiple or separate values with commas: key1=val1,key2=val2) -f, --values valueFiles specify values in a YAML file (can specify multiple) (default [])
]]><p><a href="https://helm.sh/">Helm</a>是kubernetes的官方包管理工具。根据官网上的描述<code>Helm is the best way to find, share, and use software built for Kubernetes.</code>可以看出helm在kubernetes社区中的定位。</p>
<p>这篇文章并不是helm的入门文章,而是着重于如何在本地开发chart。希望进行helm入门的同学可以参考官方文档。</p>Helm中如何传递valuehttps://www.purewhite.io/2018/01/17/helm-provide-value/2018-01-17T03:25:15.000Z2021-12-02T12:51:07.000ZHelm是kubernetes的官方包管理工具。根据官网上的描述Helm is the best way to find, share, and use software built for Kubernetes.可以看出helm在kubernetes社区中的定位。
]]><p><a href="https://helm.sh/">Helm</a>是kubernetes的官方包管理工具。根据官网上的描述<code>Helm is the best way to find, share, and use software built for Kubernetes.</code>可以看出helm在kubernetes社区中的定位。</p>
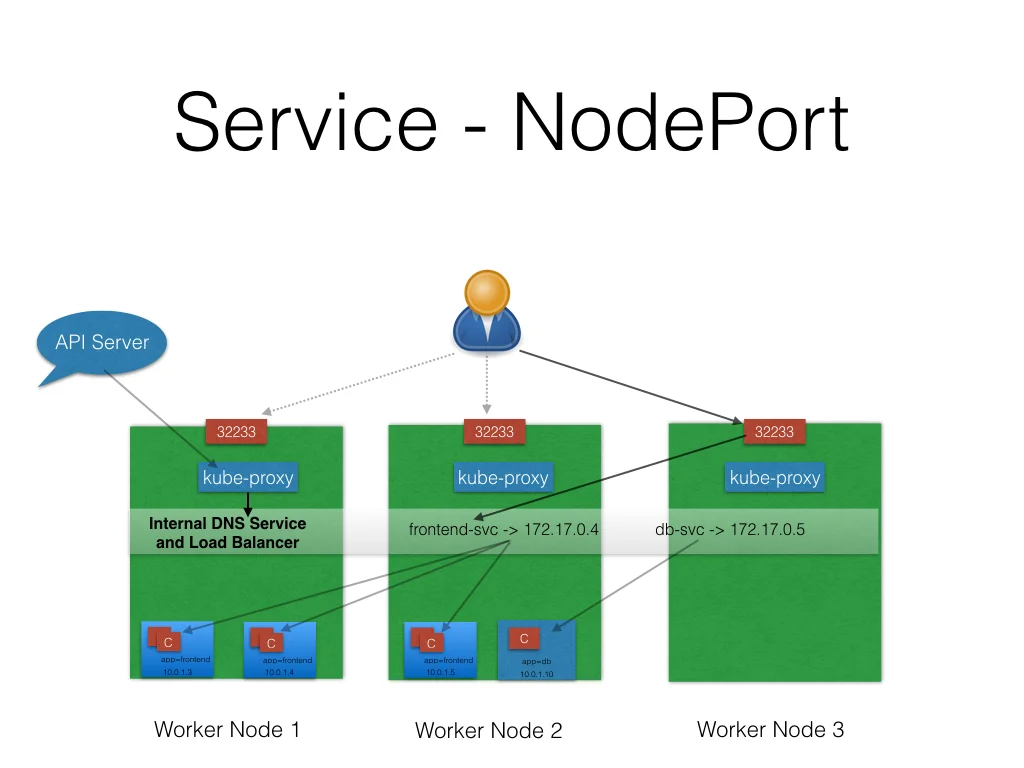
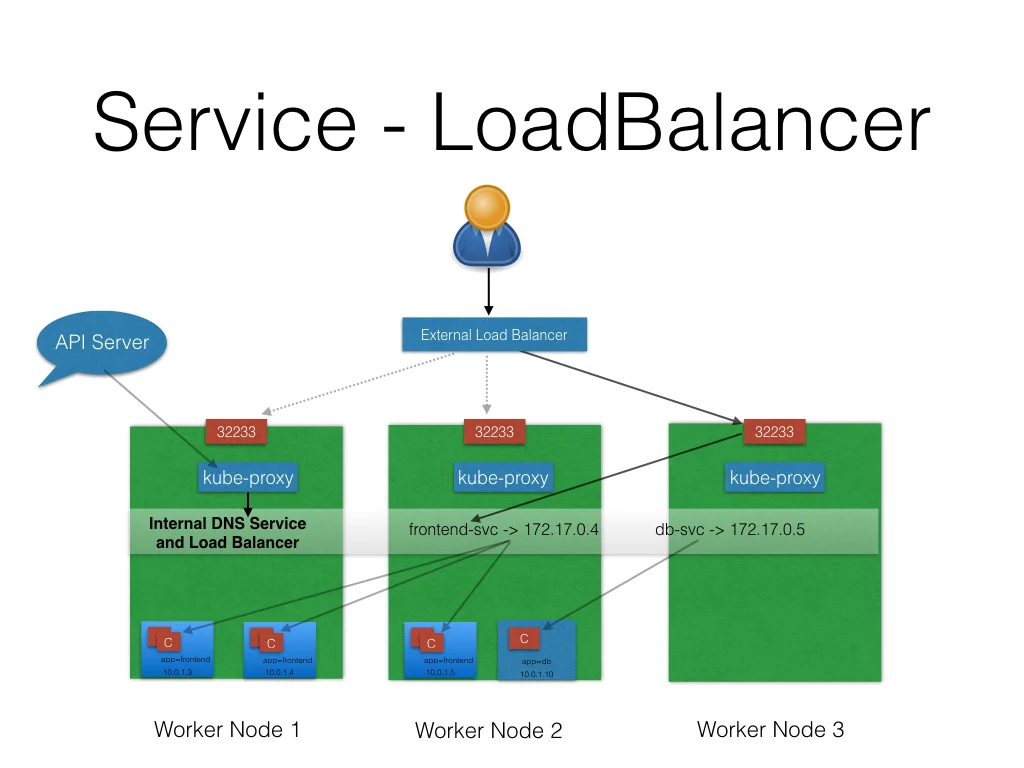
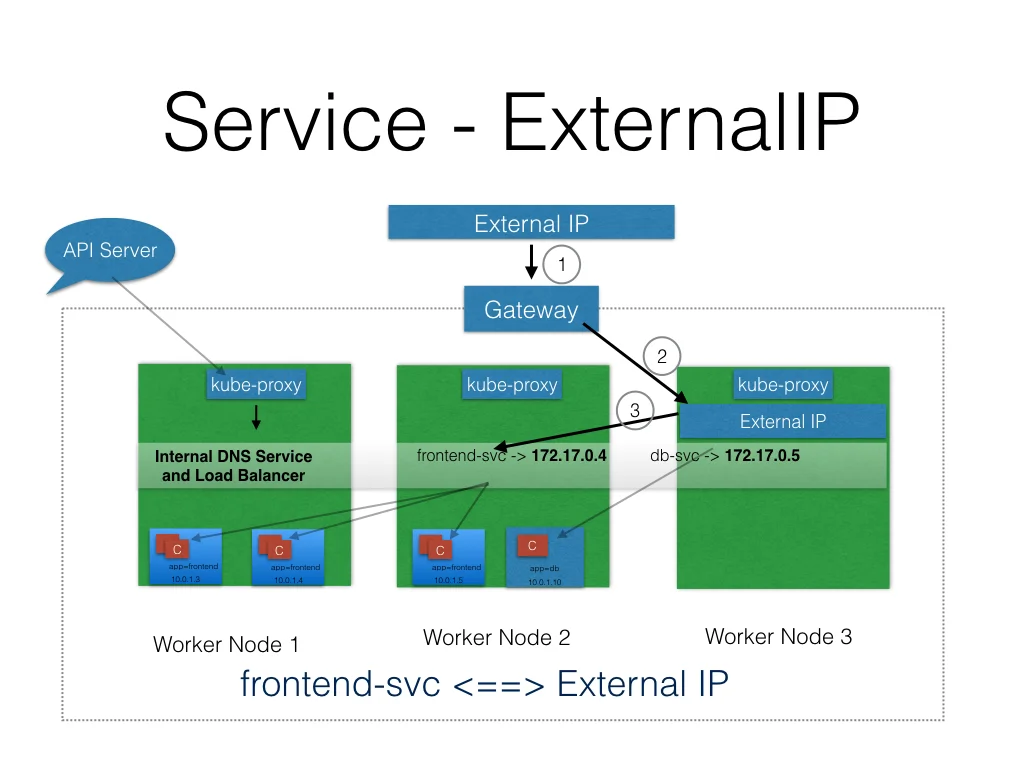
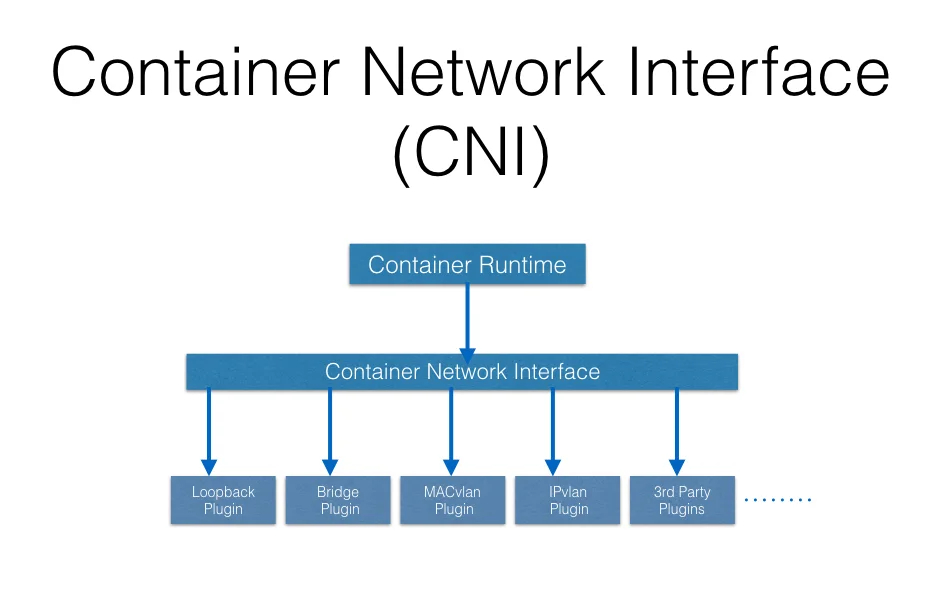
<p>这篇文章并不是helm的入门文章,而是着重于helm中的chart之间如何传递value。希望进行helm入门的同学可以参考官方文档。</p>Kubernetes中的Networkhttps://www.purewhite.io/2018/01/08/kubernetes-network/2018-01-08T08:01:50.000Z2021-12-02T12:51:07.000ZKubernetes 处理网络的方式和Docker不同,主要需要解决四种问题:
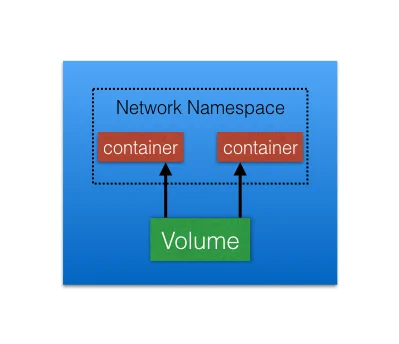
高度耦合的Container之间的网络通信:这个由Pod和localhost通信解决了;
Pod和Pod之间的网络通信,这个是本篇的主要内容;
Pod和Service之间的通信,这个是由Service解决的;
外部Service和内部Service之间的通信,这个也是由Service解决的。
简介
Kubernetes 假设 Pod 之间可以互相通信,无论它们在哪个主机上。我们给每个Pod一个单独的IP地址,那么我们就不用专门在Pod之间创建链接,或者映射container的port到主机的port来使得外部可以访问到container了。这使得我们创建了一个非常干净,向后兼容的模型,在这个模型里面Pod可以就被当做为一个VM或者甚至一个物理机,这给了我们很多方面的方便,比如port的分配,命名,服务注册、发现,负载均衡,应用程序设置和迁移等。
# Create a file with password $ echo'mysqlpassword' > password.txt # Make sure there is no trailing newline in the file, after our password. # To remove any newline, we can use the trcommand: $ tr -Ccsu '\n' < password.txt > .strippedpassword.txt && mv .strippedpassword.txt password.txt # Create the Secret $ kubectl create secret generic my-password --from-file=password.txt secret "my-password" created
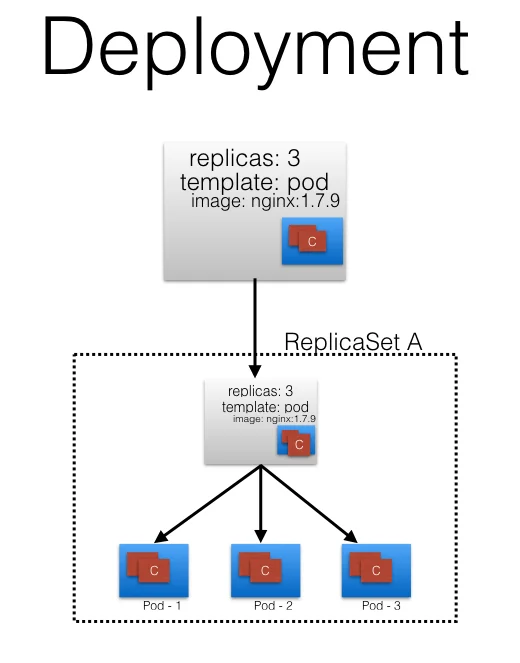
The core workloads API, which is composed of the DaemonSet, Deployment, ReplicaSet, and StatefulSet kinds, has been promoted to GA stability in the apps/v1 group version. As such, the apps/v1beta2 group version is deprecated, and all new code should use the kinds in the apps/v1 group version.
]]><p>最近正在复习准备考试,于是一边复习一遍写成博客,印证自己所学。</p>《Head First 设计模式》读书笔记0.5 —— 引子https://www.purewhite.io/2017/12/21/design-pattern-opening-words/2017-12-21T09:23:12.000Z2021-12-02T12:51:07.000Z为什么引子我还要写一篇文章呢?因为引子介绍了很多关于大脑认知的知识,这本书运用了其中的很多知识来写作,这也是这本书为什么如此火如此出名的原因。我认为这可能会对我工作或者学习产生帮助,所以记录下来。
[centos@ip-172-31-24-49 ~]$ uname -a Linux ip-172-31-24-49.ap-northeast-1.compute.internal 3.10.0-693.5.2.el7.x86_64 #1 SMP Fri Oct 20 20:32:50 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
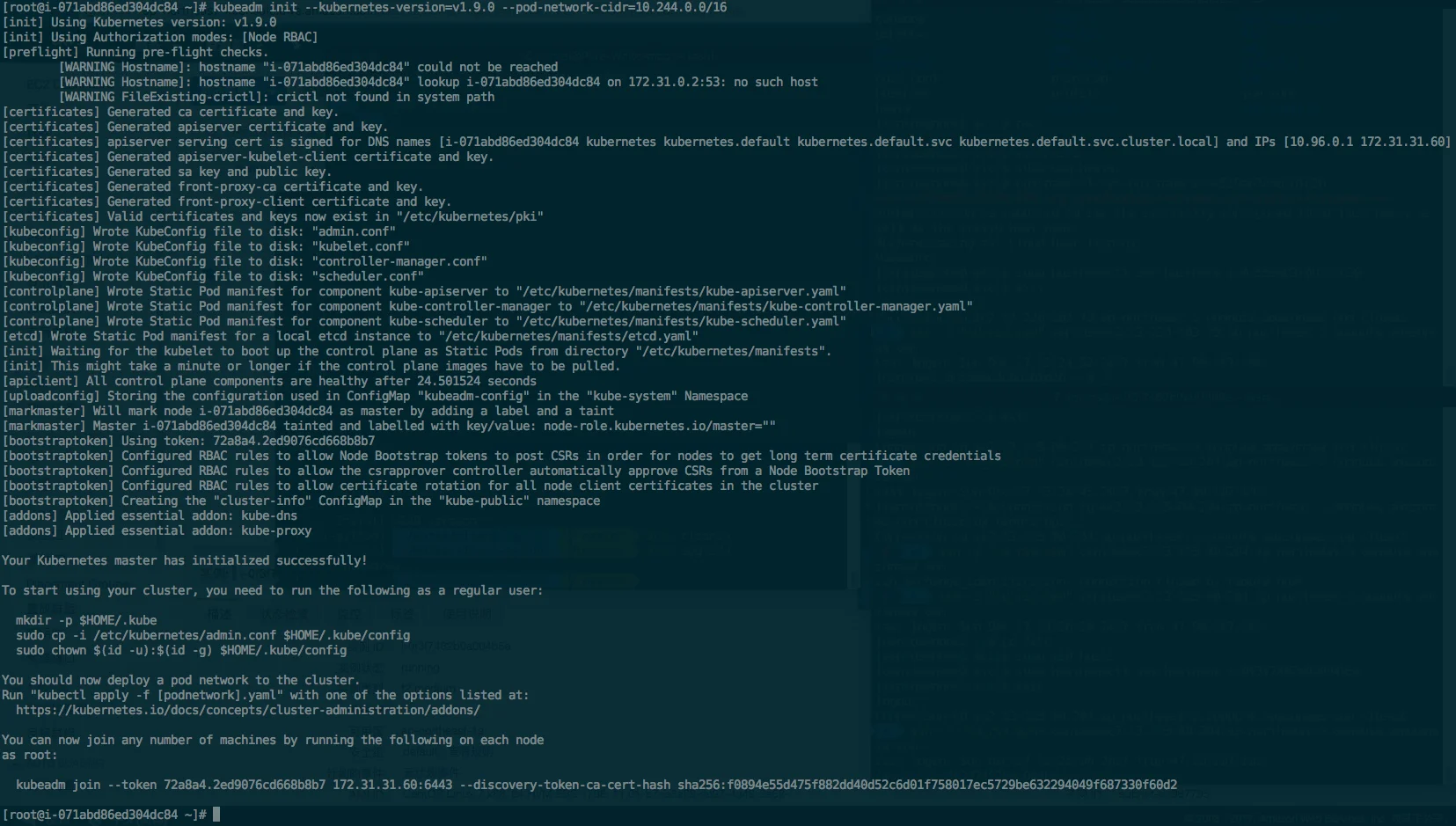
[root@i-071abd86ed304dc84 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION i-071abd86ed304dc84 Ready master 12m v1.9.0 i-0c559ad3c0b16fd36 Ready <none> 1m v1.9.0 i-0f3f7462b0a004b5e Ready <none> 47s v1.9.0
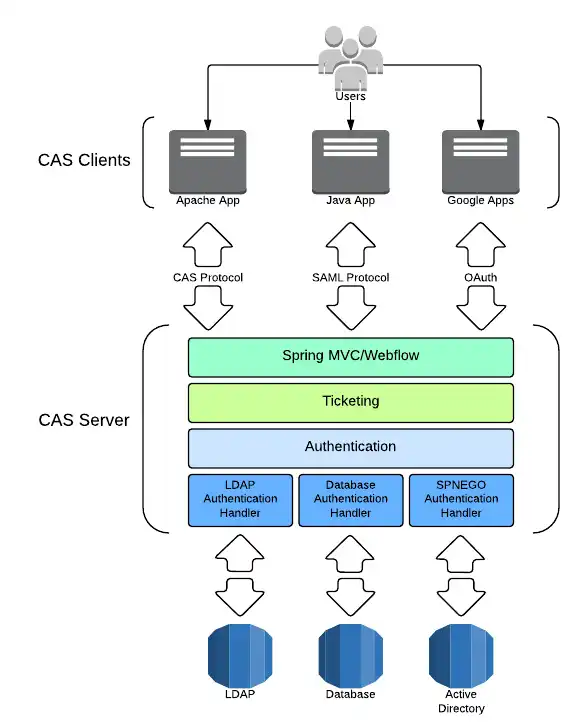
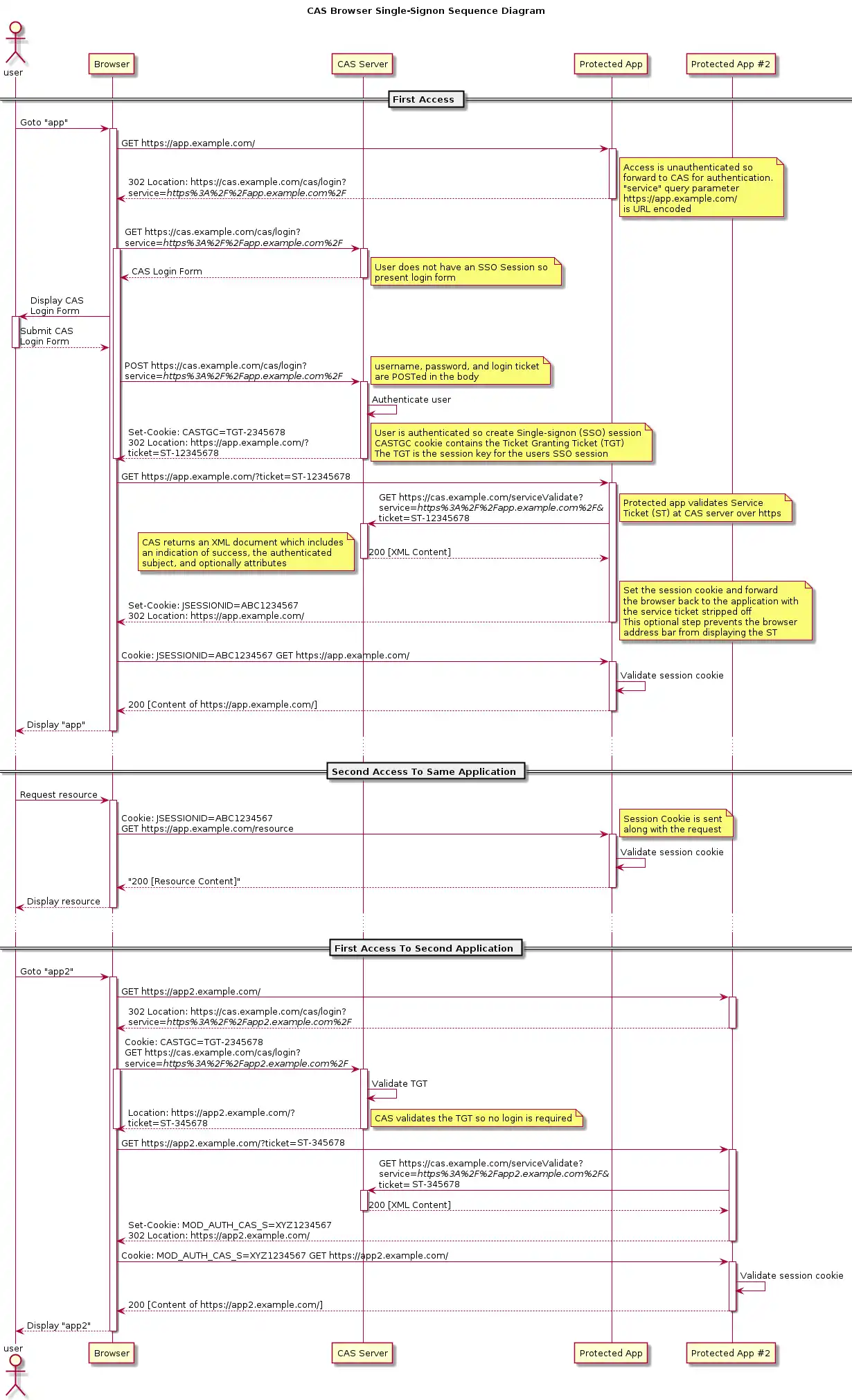
CAS Server验证完了身份,就给一个ST,让用户拿给app,app用ST去CAS Server获取到用户的信息,于是创建session。
]]><p>工作需要学习CAS,所以边学边写博客来印证自己所学。</p>
<p>CAS——Central Authentication Service,集中式认证服务,顾名思义就是把一个网站群的用户认证挪到同一个地方去进行。</p>《Head First 设计模式》读书笔记0 —— 总览https://www.purewhite.io/2017/12/11/design-pattern-overview/2017-12-11T11:56:07.000Z2021-12-02T12:51:07.000Z开始看《Head First 设计模式》,接下来(可能)会写一系列的博客关于设计模式,先在这里挖个坑。。。
]]><p>开始看《Head First 设计模式》,接下来(可能)会写一系列的博客关于设计模式,先在这里挖个坑。。。</p>如何在Mac上卸载Pythonhttps://www.purewhite.io/2017/05/21/how-to-delete-python-on-mac/2017-05-21T09:47:46.000Z2021-12-02T12:51:07.000Z
Remove the symbolic links in /usr/local/bin that point to this Python version see ls -l /usr/local/bin | grep '../Library/Frameworks/Python.framework/Versions/2.7' and then run the following command to remove all the links:
1 2
cd /usr/local/bin/ ls -l /usr/local/bin | grep '../Library/Frameworks/Python.framework/Versions/2.7' | awk '{print $9}' | tr -d @ | xargs rm
If necessary, edit your shell profile file(s) to remove adding /Library/Frameworks/Python.framework/Versions/2.7 to your PATH environment file. Depending on which shell you use, any of the following files may have been modified: ~/.bash_login, ~/.bash_profile, ~/.cshrc, ~/.profile, ~/.tcshrc, and/or ~/.zprofile.
]]><ol>
<li><p>Remove the Python 2.7 framework</p>
<p><code>sudo rm -rf /Library/Frameworks/Python.framework/Versions/2.7</code></p>
</li>
<li><p>Remove the Python 2.7 applications directory</p>
<p><code>sudo rm -rf "/Applications/Python 2.7"</code></p>
</li>
<li><p>Remove the symbolic links in <code>/usr/local/bin</code> that point to this Python version see <code>ls -l /usr/local/bin | grep '../Library/Frameworks/Python.framework/Versions/2.7'</code> and then run the following command to remove all the links:</p>
<figure class="highlight sh"><table><tr><td class="gutter"><pre><span class="line">1</span><br><span class="line">2</span><br></pre></td><td class="code"><pre><span class="line"><span class="built_in">cd</span> /usr/local/bin/</span><br><span class="line"><span class="built_in">ls</span> -l /usr/local/bin | grep <span class="string">'../Library/Frameworks/Python.framework/Versions/2.7'</span> | awk <span class="string">'{print $9}'</span> | <span class="built_in">tr</span> -d @ | xargs <span class="built_in">rm</span></span><br></pre></td></tr></table></figure>
</li>
<li><p>If necessary, edit your shell profile file(s) to remove adding <code>/Library/Frameworks/Python.framework/Versions/2.7</code> to your <code>PATH</code> environment file. Depending on which shell you use, any of the following files may have been modified: <code>~/.bash_login</code>, <code>~/.bash_profile</code>, <code>~/.cshrc</code>, <code>~/.profile</code>, <code>~/.tcshrc</code>, and/or <code>~/.zprofile</code>.</p>
</li>
</ol>MySql存储引擎的比较https://www.purewhite.io/2017/05/20/mysql-engines-compare/2017-05-19T16:44:21.000Z2021-12-02T12:51:07.000Z众所周知,MySql提供了很多存储引擎,这里来比较一下常见引擎的优劣。
查看所有存储引擎
我们可以通过show engines命令来看到我们的mysql server提供了哪些引擎:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
show engines; +--------------------+---------+----------------------------------------------------------------+--------------+------+------------+ | Engine | Support | Comment | Transactions | XA | Savepoints | +--------------------+---------+----------------------------------------------------------------+--------------+------+------------+ | InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES | | MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO | | MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO | | BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO | | MyISAM | YES | MyISAM storage engine | NO | NO | NO | | CSV | YES | CSV storage engine | NO | NO | NO | | ARCHIVE | YES | Archive storage engine | NO | NO | NO | | PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO | | FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL | +--------------------+---------+----------------------------------------------------------------+--------------+------+------------+ 9 rows in set (0.00 sec)
IMPORTANT NOTES: - Congratulations! Your certificate and chain have been saved at /etc/letsencrypt/live/example.com/fullchain.pem. Your cert will expire on 2017-07-26. To obtain a new or tweaked version of this certificate in the future, simply run certbot again. To non-interactively renew *all* of your certificates, run "certbot renew" - If you lose your account credentials, you can recover through e-mails sent to sammy@example.com. - Your account credentials have been saved in your Certbot configuration directory at /etc/letsencrypt. You should make a secure backup of this folder now. This configuration directory will also contain certificates and private keys obtained by Certbot so making regular backups of this folder is ideal. - If you like Certbot, please consider supporting our work by: Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate Donating to EFF: https://eff.org/donate-le








 ]]>
]]>



















 ]]>
]]>